#1. Knowledge
I’m building a personal agent called concierge. For now, it can answer questions about me and read my bookmarks.
Principles
I set three ground rules for this experiment:
-
Independence: The agent must be agnostic of the underlying language model. High-quality, context-rich data is the core.
-
Utility: Every new feature should add some unique functionality, making it genuinely helpful rather than just clever.
-
Collaboration: The agent should re-invent the wheel as little as possible and play well with other services and agents.
Architecture
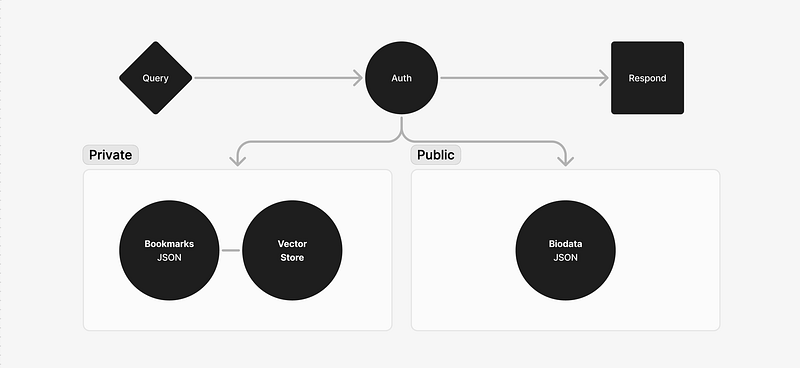
The agent’s knowledge is currently fed from two JSON files: biodata.json and bookmarks.json.
When concierge receives a query, it decides whether the query is about me or about my bookmarks. Information about me is public, so it responds to all such requests. Try it here: concierge.opemipo.com
But if the query is about my bookmarks, it checks for authentication. We currently use privy.io for this.
Vector Storage
The first prototype worked by loading my entire biodata from a JSON file into a system prompt, but my bookmarks exceed the model’s “context window” — the word-count limit.
To solve this, I used a vector store to filter the bookmarks based on the query. As I understand it, vector stores work by transforming text into numbers and then searching for similar numbers.
Here’s what that looks like:
import { OpenAIEmbeddings } from "@langchain/openai";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
export async function storeBookmarkData(bookmarksJson: string) {
const embeddings = new OpenAIEmbeddings();
const bookmarks = JSON.parse(bookmarksJson);
const documents = bookmarks.map((bookmark: any) => ({
pageContent: `${bookmark.title}\n${bookmark.url}\n${bookmark.excerpt || ""}\n${bookmark.folder || ""}`,
metadata: {
date: bookmark.created,
url: bookmark.url,
cover: bookmark.cover,
tags: bookmark.tags,
note: bookmark.note,
highlights: bookmark.highlights,
favorite: bookmark.favorite,
},
}));
return await MemoryVectorStore.fromDocuments(documents, embeddings);
}
Tools
When a query is received, the model decides whether it’s a question about me or a question about my bookmarks. If it’s a question about my bookmarks, it uses a “tool” instead of responding.
const relevantContext = `Here's what you know about the human: ${JSON.stringify(bio)}\n`;
const systemMessage = {
role: "system",
content: `${SYSTEM_PROMPT}\n
${relevantContext}\n
Use this information to answer questions about the human accurately.
If a user requests to be logged in, use the login tool to do this and the logout tool to logout users.
If a user asks questions about saved links, websites, or bookmarked content use the searchBookmarks tool to handle this.
If asked about something not in this data, politely state that you don't have that information.`,
};
concierge now has three tools:
- login: authenticates the user
- logout: removes the user’s authentication
- searchBookmarks: queries the vector store Here’s what that last one looks like:
const searchBookmarksTool = tool(
async ({ query }: { query: string }) => {
if (!user) {
return "This user is not authorized to query bookmarks";
}
if (!bookmarksVectorStore) {
return "Bookmarks data not found";
}
const bookmarksDocsWithScores =
await bookmarksVectorStore.similaritySearchWithScore(query, 2);
return bookmarksDocsWithScores
.filter(([_, score]) => score > 0.7)
.map(([doc, _]) => `${doc.pageContent}`);
},
{
name: "searchBookmarks",
description:
"This tool handles questions about saved links, websites, or bookmarked content.",
schema: z.object({
query: z.string().describe("The query to use in your search."),
}),
},
);
Search Logic
The current search logic filters for bookmarks based on their similarity to the query. This only works for specific types of request.
For example, if I ask a general question like “what are my bookmarks about?” or “how many graphic design bookmarks do you have?”, the agent will return a silly result. But if I ask a specific question like “Please share the bookmark about X?”, it answers correctly.
I’ve explored different ways to solve this problem, including switching to a structured search for certain queries. But back to Principle 3, I think it’s best to rely on a database service that’s already optimised for this.
Next
I’ve learnt a lot about data storage and LLM tools from building this. Sets the foundation for other agent capabilities.
My next challenge is to get the agent to order food for me. The agent will check the restaurant’s menu, message them, and pay.
Thanks to Tosin, Timi and Justin for your help!